I came across a set of notes written by Paul Hammond concerning the recent lecture given to the royal society by Tim Berners-Lee. One of the interesting point Paul brings up is the fact that despite living in a connected environment, the connections aren’t all that strong. Specifically most of the time the connection is the ubiquitous copy and paste scenario.
A goal of the semantic web is to provide both human readable documents as well as machine processable documents in the same package. For example it is quite easy for a human to recognise a date format (in one of the myriad ways it might be formatted), but for a computer to unambiguously recognise a date in a potential multitude of formats is more difficult. In his notes, Paul outlined what he did with an e-mail he received concerning the lecture:
When an e-mail came round the office about this evenings talk, the first thing I did was type the date into my calendar. I then looked up the address on a map site, and put a link into the appointment. I also added some quick notes about the subject of the talk. I then forwarded the info on to several friends who might be interested. They probably did the same thing. At every step, I had to manually cut and paste the information between applications, as did everyone else.
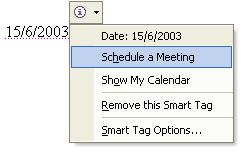
When I hear stories like this I am reminded of Microsofts attempts to introduce “Smart Tags”. Despite the obvious anti-microsoft feeling (which their track record may not have been unwarranted) smart tags have always seemed to me a good idea at some level. Replacing the smart tag concept with in document meta data provides a suitable platform for cross application communication. Imagine a suite of web enabled applications that were loosely coupled, now consider these applications registering an action for a specified metadata type, need an example of what the heck I’m talking about yet?
Imagine we start of with a small document fragment:
… lets meet up at around 10pm this tuesday …
Now using a sprinkling of automagic we get this fragment (the user of course only sees the original text):
… let’s meet up at around <date value=”2003-11-23 22:00:00″>10pm this tuesday</date> …
Using a bit of magic based on the date the message was written (another piece of meta data) and a few specified rules, the human readable date can be annotated with more machine processable information. By then taking the concept behind mime-types to a different level of granularity we can conceive of applications registering actions based on a specified metadata type. Given the previous sample a calendar application may associate an “add event on date” action with the date metadata. This action could then be exposed to the user in some manner (through a context menu for example).
Now for a bit of prior art: